TreasureData Tech Talk 2022で発表した内容の補足です。Hive Distributed Profiling Systemの実装方法について、プレゼンテーション中に説明しきれなかった部分を解説します。なお本記事は「Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2022」19日目の記事として執筆しました。
参考文献
先にこちらの記事と記事中で紹介されているスライドにざっと目を通すことをオススメします。
HDPSを実装する上で工夫した点の補足
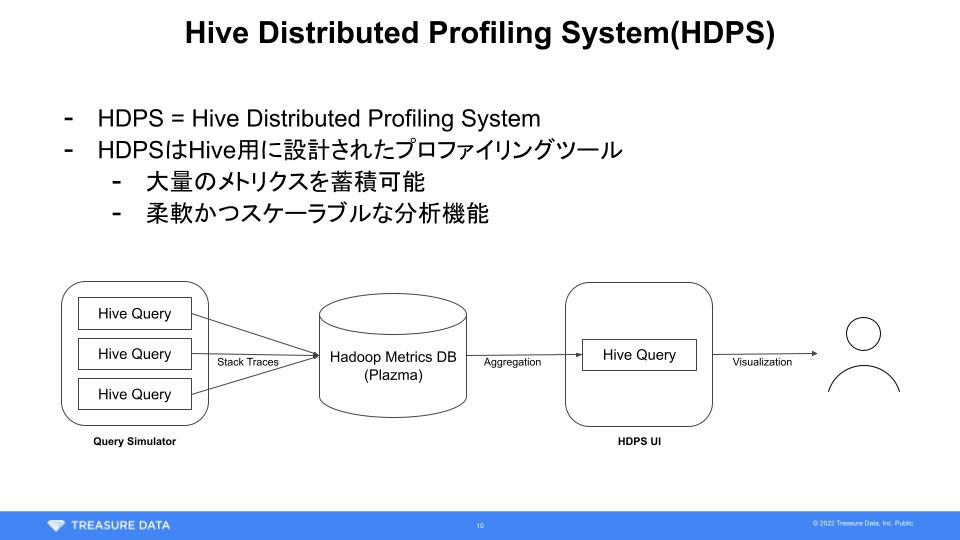
Query Simulator

クエリシミュレータは一般社会に存在しない様々なシステムに依存しているのでこの記事じゃ説明しきれません。すみません。必要ならJourney of Migrating Millions of Queries on The Cloudを読んで真似してみてください。
とはいえこれが必要なのはSaaSとしてデータプラットフォームを提供しているトレジャーデータの都合によるものが大きく、一般的に必須なツールではないと思います。
Hive on Tez + Java Flight Recorder

プロファイラを用いる際、通常はプロセス単位でスタックトレースのサンプリングを行うことが多いんじゃないでしょうか。一方HDPSはJava Flight RecorderのJava APIを用いてTezのTask Attempt単位でサンプリングを行います。
具体的にはTezのTezTaskRunner2に以下のパッチをあて、
public TaskRunner2Result run() { try (final JfrEventReporter ignored = JfrEventReporter.forTaskAttempt(task.getTaskAttemptID(), taskConf)) { // Task Attemptを実行し完了を待機するブロック ... } }
Task Attemptを実行するたび次のような処理を呼び出しています。見やすさのため異常系のハンドリングなど諸々省略しているのでご留意ください。Java 14で導入されたJFR Event Streamingを用いるともっとリアクティブかつエレガントに実装できるかもしれません。
public class JfrEventReporter implements Closeable { private final Recording recording; private final Path dumpFile; private final LinkedHashMap<String, Object> identities; public static JfrEventReporter forTaskAttempt(TezTaskAttemptID taskAttemptID, Configuration conf) { if (!conf.getBoolean("td.hive.jfr.enabled", false)) { return new NopJfrEventReporter(); } // Store Hive or Tez IDs final LinkedHashMap<String, Object> identities = new LinkedHashMap<>(); identities.put("hive_session_id", conf.get("hive.session.id")); identities.put("application_id", taskAttemptID.getTaskID().getVertexID().getDAGId().getApplicationId().toString()); ... final Map<String, String> settings = ImmutableMap .<String, String>builder() .put("jdk.ExecutionSample#enabled", "true") .put("jdk.ExecutionSample#period", "100 ms") .put("jdk.NativeMethodSample#enabled", "true") .put("jdk.NativeMethodSample#period", "100 ms") .build(); final Recording recording = new Recording(settings); final Path dumpFile = Files.createTempFile("td_", ".jfr"); recording.setToDisk(true); recording.setDestination(dumpFile); recording.start(); return new JfrEventReporter(recording, dumpFile, identities, ...); } private JfrEventReporter(...) { // 初期化 ... } @Override public void close() { this.recording.stop(); this.sendEvents(); Files.deleteIfExists(dumpFile); } private void sendEvents() { final RecordingFile file = new RecordingFile(dumpFile); while (file.hasMoreEvents()) { sendEvent(file.readEvent()); } } .... }
Tezコンテナ内で同時に処理されるTask Attemptはひとつなので、Hive on Tezの場合これだけでスタックトレースとそれに関連するID群をマッピングすることができます。処理がTezプロセスで完結しているのでYARNに手を加える必要もなくデプロイも容易です。異なるミドルウェアをプロファイリングする場合、プロセスやスレッドの実行モデル次第では追加の工夫が必要になりそうです。
Plazmaへのイベント格納

TDのサーバにはFluentdプロセスが常駐していて、特定のタグにイベントを送るとTD上のテーブルに自動的にレコードを追加してくれるようセットアップされています。スキーマの変更も勝手に検知してくれる非常に便利なシステムです。これにより、まるでRPCするかのごとく様々なメトリクスを保存することができます。この仕組みを用いてHDPSの分析に必要なスタックトレースを適当に送りつけています。
private void sendEvent(RecordedEvent event) { final String thread = event.<RecordedThread>getValue("sampledThread").getJavaName(); // デフォルトでは重要なスレッドの情報のみ送っている if (!thread.equals("TezChild")) { return; } final LinkedHashMap<String, Object> record = new LinkedHashMap<>(identities); record.put("stack_trace_id", UUID.randomUUID().toString()); record.put("event_type", event.getEventType().getName()); record.put("start_time_millis", event.getStartTime().toEpochMilli()); record.put("thread", thread); record.put("state", event.getString("state")); record.put("stack_trace", formatStackTrace(event.getStackTrace())); // SREチームが用意してくれているFluentdに送るだけ fluency.emit("tag.to.hadoop_metrics.tez_task_attempt_method_sampling", event.getStartTime().getEpochSecond(), record); } private static List<LinkedHashMap<String, Object>> formatStackTrace(RecordedStackTrace stackTrace) { return stackTrace.getFrames().stream().map(frame -> { final LinkedHashMap<String, Object> element = new LinkedHashMap<>(); element.put("class_name", frame.getMethod().getType().getName()); element.put("method_name", frame.getMethod().getName()); element.put("line_number", frame.getLineNumber()); element.put("is_java_frame", frame.isJavaFrame()); element.put("type", frame.getType()); return element; }).collect(Collectors.toList()); }
Hiveによるスタックトレースの集計

HDPSではフレームグラフを生成するためにd3-flame-graphを使用しています。d3-flame-graphは再帰的なJSONを受け取りフレームグラフを描画します。
{ "name": "<メソッド名や行数>", "value": <サンプリングされた回数>, "children": [ <Object> ] }
JavaScriptを用いて大量のスタックトレースからこのJSONを生成するのは現実的ではありません。なのでHDPSのWeb UIは分析条件に合わせて次のようなSQLを自動生成し、分散クエリエンジンであるHiveのパワーを用いて強引に集計を行っています。実際は一番上のCommon Table Expression内にあるJOINやWHERE句が巨大で、TDジョブの情報や実行計画、『Hive on Tezのメトリクスを任意のデータ基盤に蓄積する方法 - おくみん公式ブログ』で紹介しているメトリクスなどと結合しながら分析対象を絞り込みます。
-- 分析対象のスタックトレースを絞り込む WITH sampled_stack_traces AS ( SELECT stack_trace_id, ARRAY_APPEND(stack_trace, '{}') AS stack_trace FROM tez_task_attempt_method_sampling AS t JOIN other_metrics ... WHERE {condition} ), -- 一度スタックトレースを分解する frames AS ( SELECT stack_trace_id, IF( frame = '{}', '<ROOT>', GET_JSON_OBJECT(frame, '$.class_name') || '.' || GET_JSON_OBJECT(frame, '$.method_name') || ':' || GET_JSON_OBJECT(frame, '$.line_number') || ' (' || IF(GET_JSON_OBJECT(frame, '$.type') = 'Native', 'Native', 'Non-native') || ')' ) AS line, SIZE(stack_trace) - pos AS depth FROM sampled_stack_traces LATERAL VIEW POSEXPLODE(stack_trace) t AS pos, frame ), -- 再構築して集計 prefix_frequency AS ( SELECT frame_path, SIZE(frame_path) AS depth, COUNT(*) AS num FROM (SELECT COLLECT_LIST(line) OVER (PARTITION BY stack_trace_id ORDER BY depth) AS frame_path FROM frames) AS t GROUP BY frame_path ) SELECT p.frame_path[depth - 1] AS node, p.depth, p.num, ROW_NUMBER() OVER (ORDER BY p.frame_path) AS sort_id FROM prefix_frequency p CROSS JOIN (SELECT count(*) AS num FROM sampled_stack_traces) t -- d3-flame-graphがスムーズに描画できるよう、マイナーなノードを削除する WHERE p.num * 100.0 / t.num >= 1.0 ORDER BY sort_id
フレームグラフの描画

SQLの出力を前述のJSONフォーマットに変換し、d3-flame-graphに渡してあげるだけです。ドキュメント通りにやるだけなので省略します。
もっと頑張れるかもしれないポイント
プレゼン時に説明したようにHive Distributed Profiling Systemはいわゆる20%ルールの中で開発しました。本業の邪魔にならないよう、極力デプロイやメンテナンスが容易になるように実装しています。まだ手はつけていないけど、もう少し工夫の余地があるかもと感じる部分もあるので追記しておきます。
事前に集計したテーブルを作っておく
ここで紹介した手法は最も原始的なフォーマットでスタックトレースを分散ストレージに格納しています。これはPlazmaとHiveのスケーラビリティに甘えることで実装の単純さとデリバリーの速度を優先した結果と言えます。
場合によっては容量や分析クエリの性能の都合で全量のスタックトレースを保存しておくことが難しいケースもあるでしょう。その場合スタックトレースとその出現回数のペアを保存しておけば少なくともフレームグラフを生成する分には十分です。送信元でできるだけ要約してもいいし、一度分散ストレージに格納してから加工してもよさそうです。これにより劣化する情報はスタックトレースの取得時刻くらいかなと思います。
LINEさんのKafka調査事例のように、ミドルウェアが変な挙動をしていたタイミングで何が起きていたのかを確かめるユースケースがある場合はとりあえず全量取っておくのもありですね。
Async Profiler
Java Flight Recorderを用いたのはインストール不要で利用でき、またAPIが十分に使いやすかったからです。
Async Profilerもいろんなところで使われていて割と関心があります。この記事で紹介しているような用途ではAsync ProfilerのWall-clock profilingが便利そうに見えます。Java APIがありJFR互換のファイルを出力できるようなので、メリットがあるなら置き換えることも検討したいです。
終わりに
以上、Hive Distributed Profiling Systemの実装方法を発表時より少しだけ詳しく説明しました。最終的に各々のデータプラットフォームと連携する必要があるため、開発コストゼロで導入できるといった類のものではありません。とはいえ標準的なデータプラットフォーム、つまりストリーミングインサート可能な分散ストレージとスケーラブルなクエリエンジンさえあれば特別な努力をせずとも実装できるという点はご理解いただけたかと思います。
HDPSはHive用のプロファイリングツールです。ただしサンプリングしたスタックトレースをビッグデータ基盤に格納するアイデアや、この記事で紹介したような実装上のテクニックは、特にミドルウェアの問題を突き止める上では普遍的に有用であると思っています。この手のシステムを運用する人々は年々減っているような気がしますが、誰かの助けになればと思いとりあえず記事にしてみました。