少し間が空いてしまいましたが、引き続きHive 4に関するアップデートを紹介していきます。今回はパフォーマンス改善についてまとめてみます。
Hive 4関連記事一覧
Vectorization
Vectorizationは複数行をまとめて処理することでメモリレイアウト含む実行効率を改善する仕組みです。最低限よく使われる機能からvectorizationの対応がスタートし、その後継続的にサポート範囲の拡大やさらなる最適化が行われています。
ざっと見る限り、Hive 3.0.0から4.0.0の間で43個もの関連チケットがクローズされています。
CBO
HiveはApache Calciteを利用してCost Based OptimizationやRule Based Optimizationを実装しています。頻繁に新規最適化ルールの追加や既存ルールの修正・改善が行われており、Hive 3.0.0以降、136個のチケットがクローズされています。
Shared Work Optimizerの強化
Hive 3にて導入されたShared Work Optimizerも進化しています。Shared Work Optimizerは実行計画ベースで共通処理をマージする最適化機能です。
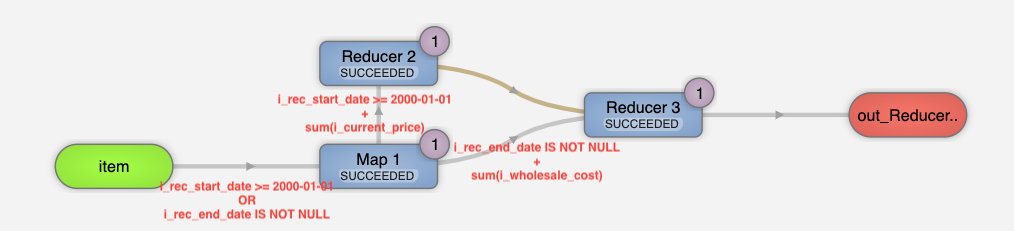
例えば次のSQLは item テーブルを i_rec_start_date でフィルタして i_current_price の総和を計算するサブクエリと i_rec_end_date でフィルタして i_wholesale_cost の総和を計算するサブクエリから構成されています。
SELECT * FROM (SELECT sum(i_current_price) FROM item WHERE i_rec_start_date >= '2000-01-01') a CROSS JOIN (SELECT sum(i_wholesale_cost) FROM item WHERE i_rec_end_date IS NOT NULL) b;
素直なクエリエンジンであれば二重にテーブルスキャンを実行するでしょう。Shared Work Optimizerを無効化して実行すると以下のように実行されます。

Shared Work Optimizerを有効にするとpredicateやprojectionのプッシュダウンがマージされた単一のテーブルスキャンオペレータが生成され、fan-outするイメージで次のReducerに必要なデータを配布します。
ツールが生成するクエリには往々にして重複するexpressionが存在します。Shared Work Optimizerはそのようなユースケースを強力にサポートするだけのポテンシャルがありそうです。この機能もHive 3からかなり進化していて、より複雑な共通処理をマージすることが可能となっています。
統計情報
Hiveは実行計画を作成する際、統計情報を駆使して各フェーズが処理・出力するであろうデータサイズを見積もります。この情報は並列度のチューニングや、JOINアルゴリズムの選択に利用されます。
Hive 4では以下に紹介するように、より洗練された統計情報や推定アルゴリズムが実装されているので、適切な物理プランが生成される可能性が高いです。統計情報系のチケットは48個が新たにクローズされています。
ここではその中から特に目新しい機能を二つ紹介しておきます。
ヒストグラム
『[HIVE-26221] Add histogram-based column statistics - ASF JIRA』にて各カラムのヒストグラムを統計情報として取得・利用できるようになりました。これにより数値のフィルタ結果などを高精度に推定できます。応用しがいがありそうなメタデータです。
> CREATE TABLE test_hist (id int); ... > INSERT INTO test_hist VALUES (0), (1), (3), (3), (3), (3), (3), (3), (7), (9); ... > DESCRIBE FORMATTED test_hist id; ... +------------------------+----------------------------------------------------+ | column_property | value | +------------------------+----------------------------------------------------+ | col_name | id | | data_type | int | | min | 0 | | max | 9 | | num_nulls | 0 | | distinct_count | 5 | | avg_col_len | | | max_col_len | | | num_trues | | | num_falses | | | bit_vector | HL | | histogram | Q1: 3, Q2: 3, Q3: 3 |
実行時統計情報の再利用
Hiveにはクエリの終了時や失敗時に各オペレーターの実行時統計情報を保存する仕組みがあります。これは主に、不適切な実行計画によりエラーになるケース、例えばMap Join(Broadcast Hash Join)がOOMを引き起こすケースなど、を正しい統計情報を用いてリカバーするために使用されます。Hive 4ではデフォルトの保存先がHive Metastoreになるため、前回実行したクエリを元に実行計画を最適化することも可能です。
以下の WHERE id LIKE '01%' は10行中9行を選択します。ただしそれは実行して初めて判明する情報であるため、最初はEXPLAINはヒューリスティクスによりFilter Operatorの出力が5行であると推定します。
> CREATE TABLE test (id string); ... > INSERT INTO test VALUES ('0'), ('01'), ('012'), ('0123'), ('01234'), ('012345'), ('0123456'), ('01234567'), ('012345678'), ('0123456789'); ... > set hive.query.reexecution.always.collect.operator.stats=true; ... > EXPLAIN SELECT count(*) FROM test WHERE id LIKE '01%'; ... | TableScan | | alias: test | | filterExpr: (id like '01%') (type: boolean) | | Statistics: Num rows: 10 Data size: 900 Basic stats: COMPLETE Column stats: COMPLETE | | Filter Operator | | predicate: (id like '01%') (type: boolean) | | Statistics: Num rows: 5 Data size: 450 Basic stats: COMPLETE Column stats: COMPLETE | ... > SELECT count(*) FROM test WHERE id LIKE '01%'; +------+ | _c0 | +------+ | 9 | +------+
二回目はどうでしょうか?前回実行時の生きた統計情報が保存されているため、正しい行数を見積もることができるようになります。
> EXPLAIN SELECT count(*) FROM test WHERE id LIKE '01%'; ... | TableScan | | alias: test | | filterExpr: (id like '01%') (type: boolean) | | Statistics: (RUNTIME) Num rows: 10 Data size: 900 Basic stats: COMPLETE Column stats: COMPLETE | | Filter Operator | | predicate: (id like '01%') (type: boolean) | | Statistics: (RUNTIME) Num rows: 9 Data size: 810 Basic stats: COMPLETE Column stats: COMPLETE |
この機能は実に凝っていて、統計情報をクエリでなくオペレータツリーのシグネチャー単位で保存します。なので、異なるステートメントの実行時統計情報を部分的に拝借することも可能です。ETL処理では同じpredicateや集約処理が繰り返し実行されることは日常茶飯事であるため、うまく使えば世界が変わる可能性もありそうです。
> EXPLAIN SELECT count(distinct id) FROM test WHERE id LIKE '01%'; ... | TableScan | | alias: test | | filterExpr: (id like '01%') (type: boolean) | | Statistics: (RUNTIME) Num rows: 10 Data size: 900 Basic stats: COMPLETE Column stats: COMPLETE | | Filter Operator | | predicate: (id like '01%') (type: boolean) | | Statistics: (RUNTIME) Num rows: 9 Data size: 810 Basic stats: COMPLETE Column stats: COMPLETE |
総評
Shared Work Optimizerや実行時統計情報再利用のような、エンタープライズデータウェアハウス!って感じの機能が順当に進化していてよかったです。開発者として利用・改良しがいもあるので、どんどん触っていこうと思っています。