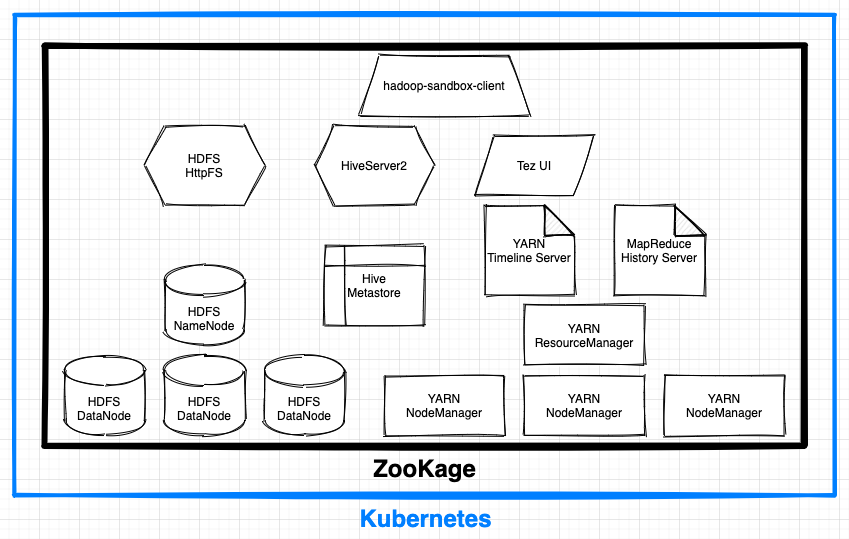
Kubernetes上にHadoopサンドボックス環境をコマンド一発で構築するツール、ZooKageをリリースしました。本記事では開発に至った経緯と基本的な使い方を紹介します。
「Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2020」にエントリーするつもりでいましたが、開発中に枠が埋まってしまったので過去の日付を埋める形で参加させていただきます。遅くなってすみません……
モチベーション
Hadoopエコシステムは大量のコンポーネントから成り立っており、その混沌はしばしば動物園に例えられます。手軽に起動する手段が用意されているプロジェクトもありますが、それでもローカルマシンで満足な検証をするには困難を伴います。公私ともに様々なバージョンのHive/Hadoopやそれらへのパッチを検証することがあるため、気軽にHadoopクラスタ一式を用意できるようにしたいと思って開発を始めました。
最終的に、Kubernetesを用いることでパッケージ化されたHadoopクラスタをサンドボックス環境にスッとと立ち上げることのできる何かが出来上がりました。
下準備
必要な支度はなんとDocker Desktopのインストールといくつかの設定変更のみ。
ZooKageそのものはKubernetesへのデプロイ設定を記述したマニフェストとちょっとしたヘルパーコマンド群で構成されています。KubernetesはDocker Desktopがネイティブにサポートしており、設定変更のみで導入できます。マニフェストはKustomizeで管理しています。KubernetesのCLIツールに同梱されているため追加のインストールは不要です。
YARNを分散モードで起動するのでメモリはそれなりに必要です。NodeManagerの設定値yarn.nodemanager.resource.memory-mbに応じてDocker Desktopに割り当てるRAMのサイズを増やしてあげてください。デフォルト設定の場合とりあえず8GBあれば十分です。基本的にマシンスペックはそこまで高くなくても大丈夫だと思います。著者はMacBook Airを使用しています。
なお、Docker Desktop for Mac以外での動作確認はしていません。少なくとも普通のマルチノードKubernetesクラスタ上では動きません。プロダクショングレードなHadoopクラスタを運用したい場合はClouderaの製品やApache Bigtopなどを用いるとよいでしょう。奇しくも今年はBigtopの解説記事が大量に生み出された年でもありました。
- Apache Bigtop の概要と最新動向 | sekikn.github.io
- Bigtop が提供するパッケージを使って Hadoop クラスタを構築する | sekikn.github.io
- Bigtop の Puppet マニフェストを使って Hadoop/Spark クラスタの構築を自動化する | sekikn.github.io
- Bigtop のスモークテストを使って Hadoop/Spark クラスタの動作確認を行う | sekikn.github.io
- Bigtop の provisioner を使って仮想マシンやコンテナ上に Hadoop/Spark クラスタを構築する | sekikn.github.io
まとめると必要な作業は以下の3つです。
- Docker Desktopのインストール
- Kubernetesの有効化
- メモリ設定の変更
使い方
まず立ち上げるコンポーネントの種類やバージョンをkustomization.yamlで指定します。内部で使われているライブラリのバージョンが衝突しないよう、READMEに書かれている組み合わせを選ぶ必要があります。
namespace: zookage commonLabels: owner: zookage bases: - base/common - base/hdfs - base/yarn - base/tez - base/mapreduce - base/hive - base/client images: - name: zookage-hadoop newName: zookage/zookage-hadoop newTag: "3.1.4-zookage-0.1" - name: zookage-hive newName: zookage/zookage-hive newTag: "3.1.2-guava-27.0-jre-zookage-0.1" - name: zookage-tez newName: zookage/zookage-tez newTag: "0.9.2-guava-27.0-jre-jersey-1.19-servlet-api-3.1.0-without-jetty-zookage-0.1" - name: zookage-util newName: zookage/zookage-util newTag: "0.1.0"
上記の設定であれば以下のコンテナが起動します。
- HDFS NameNode × 1
- HDFS DataNode × 3
- HDFS HttpFS × 1
- YARN ResourceManager × 1
- YARN NodeManager × 3
- YARN Timeline Server × 1
- MapReduce History Server × 1
- Tez UI × 1
- Hive Metastore × 1
- HiveServer2 × 1
- クライアントライブラリ一式がインストールされたコンテナ × 1
次に ./bin/up コマンドを実行します。初回はDockerイメージのダウンロードが必要なので少し時間がかかります。二回目以降は2~3分程度でDBの初期化等含め全コンポーネントのセットアップが完了します。
$ git clone --branch v0.1.0 git@github.com:zookage/zookage.git $ ./bin/up namespace/zookage created job.batch/package-hadoop created job.batch/package-hive created job.batch/package-tez created ... All resources are ready!
クラスタで遊ぶには、ZooKageが用意してくれるクライアントコンテナを使用すると便利です。./bin/sshでログインすると、例えば次のようにbeelineコマンドでHiveジョブを実行することができます。
$ ./bin/ssh zookage@zookage-client-0:~$ beeline Connecting to jdbc:hive2://hive-hiveserver2:10000/default;password=dummy;user=zookage Connected to: Apache Hive (version 3.1.2) Driver: Hive JDBC (version 3.1.2) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 3.1.2 by Apache Hive 0: jdbc:hive2://hive-hiveserver2:10000/defaul> SELECT 1; ... +------+ | _c0 | +------+ | 1 | +------+ 1 row selected (1.314 seconds)
他にもWeb UIへアクセスしたり、自分で任意のリビジョンのDockerイメージを作成して起動したりすることができます。詳しくはリポジトリのREADMEをご覧ください。
まとめ
以上、ZooKageの導入方法と基本的な使い方の紹介でした。Kubernetes上にミドルウェアをデプロイするのはチャレンジングだと言われて久しいですが、分散システムをローカルマシンで検証する分には十分に便利です。
せっかくなのでHive/Hadoop以外にも個人的に興味のあるApache Ozoneなどを追加しようと思っています。Kubernetesを使っているのでApache YuniKornやSpark on k8s、Flink on k8sなんかも試せるかもしれません。なにかおもしろいアイデアがあったらぜひ教えてください。