4月某日、Hiveのメーリングリストに『HiveのデフォルトテーブルフォーマットをIcebergにしてはどうか』という提案が投稿されました。賛否はあるもののこの提案が現実的に思えるほど、HiveコミュニティはIcebergやData Lakehouseとのインテグレーションに多くのリソースを費やしています。
この記事では私が関わっているものを中心に、今後のリリースで追加されそうな面白機能を紹介していきます。
最近の開発動向
カタログとしてのHive Metastore
Hive Metastore(HMS)は言わずとしれたデータ基盤向けのメタデータサービスです。HDFSやAmazon S3上にあるファイルに加えPostgreSQL、Apache HBase、Apache Kafkaなどあらゆるストレージに保存されているデータをテーブルとして管理することができます。中でもIcebergテーブルはそれに特化した機能が開発されるほど手厚くサポートされています。
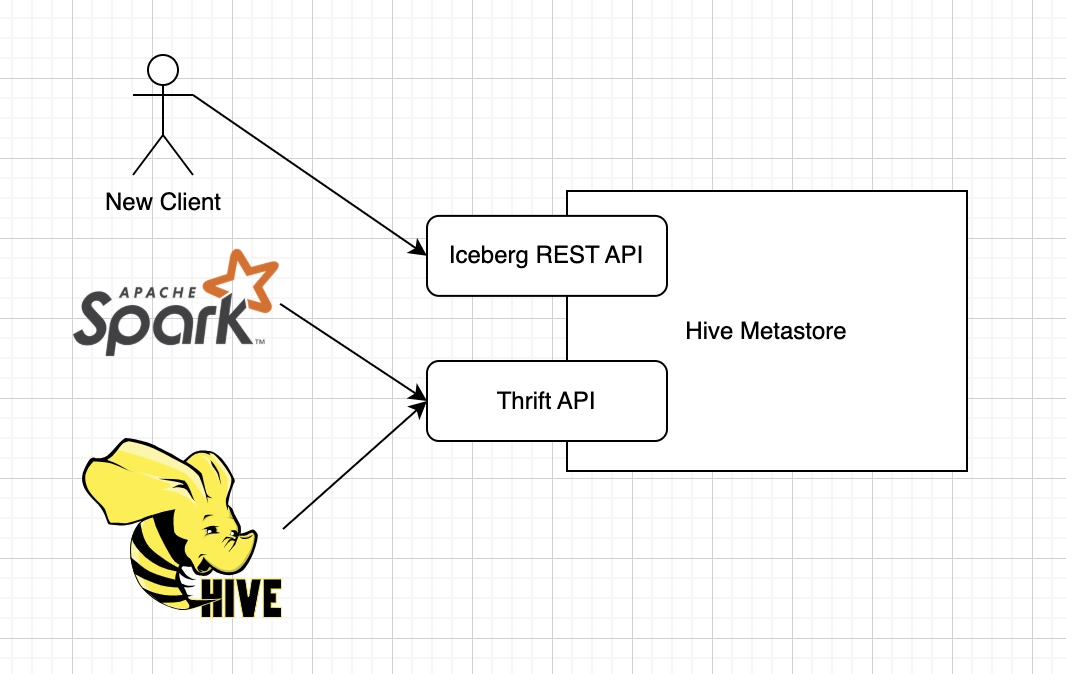
Iceberg REST Catalog APIの提供
Icebergクライアントは様々なメタデータリポジトリをカタログとして使用することができます。RDBMSを直に用いたり、AWS Glue Data Catalogを用いたり。オープンな選択肢としては、Hive Metastoreも代表的なものの一つでしょう。それら数多くの選択肢の中で一際脚光を浴びているのが、Iceberg REST Catalogです。詳細はBering氏の『Apache Iceberg Catalogの選択肢 - Bering Note – formerly 流沙河鎮』に譲るとして、ここで重要なのはIcebergプロジェクトが策定するREST APIを実装すると、誰もがIcebergカタログをネットワーク越しに提供できるという点です。
Hive MetastoreのサーバはRPCフレームワークであるApache Thriftにより実装されています。Hive Metastoreは業界標準といっても差し支えないほど普及しているため、現状はIcebergをサポートするツールやクエリエンジンのほぼすべてがHMS Thrift APIを直接Icebergカタログとして使用することができます。ただ、今後はIcebergネイティブなツールが増えてきたり、あるいはIceberg自身もREST Catalogを前提に進化したりする可能性があるでしょう。ということが念頭に置かれているのかはわからないですが、Hive Metastoreに直接Iceberg REST Catalog APIを実装するpull requestが先日マージされました。
これにより、既存のHiveクライアントはThrift APIを用いつつ、Thriftに非対応なIcebergクライアントはIceberg REST APIでHive Metastoreを操作する、といったことが可能になります。
細かい部分にバグがありmasterブランチをビルドしてもおそらくまだ動きませんが、将来が楽しみなので個人的に支援しています*1。
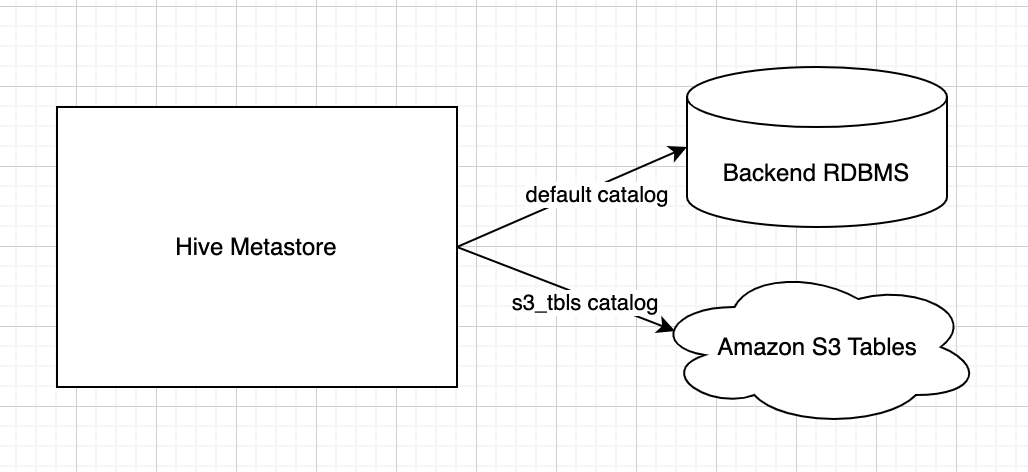
Federated Catalog構想
少なくないIcebergユーザーが、クラウドプロバイダやクラウドDWHのIcebergサポートに大きな期待を寄せていることでしょう。私もその一人で、先日はAmazon S3 Tablesのハンズオンに参加し、色々便利にできているものだなと感心したものです。
S3 Tablesのようなサービスが増えると、おそらくこのIcebergテーブルはAWSが管理しているけどこのIcebergテーブルはSnowflakeが管理していて、さらに自分で用意した普通のS3にもIcebergテーブルがある!といった状況が発生しそうです。こういう状況を見越してか、外部のIceberg REST Catalogをネームスペースごと参照できるようにするプロジェクト、『[HIVE-28879] Federated Catalog support - ASF JIRA』が爆誕しました。ユースケースについては皆様のご意見をお聞かせいただきたいところですが、HMSをSingle Source of Truthとして使う上で重要そうに見えます。
ストレージエンジンとしてのHive
Icebergテーブルの参照や更新操作の99%は圧倒的な信頼性を誇るAmazon S3やGoogle Cloud Storageで完結するため、一見簡単に運用できそうな感じがします。とはいえ現実的にはいわゆるsmall files problemを解消したり、一定期間を経過したスナップショットを削除したりしないとIcebergを上手に使いこなすことはできません。Hiveには元々Hiveネイティブなテーブルをメンテナンスするための仕組みが充実しており、それを基盤としてIcebergテーブルをメンテナンスする機能が実装されています。
コンパクション
いわゆるビッグデータに触れたことがある方なら誰もが小さすぎるParquetファイルをマージしたり、逆に大きすぎるファイルを分割したくなったことがあることでしょう。さらにIcebergの場合パーティショニング方法を柔軟に変更できるため、最適でないパーティション定義が残ってしまい、クエリエンジンのパフォーマンスに影響を与えることもあります*2。
HiveにはACIDテーブル*3に対してメジャー・マイナーコンパクションを実行する構文が存在します。我々はそれらのコマンドをIcebergテーブルに対しても使えるよう拡張しており、高頻度で改善や機能追加が行われています.
ALTER TABLE tbl COMPACT 'major'; -- 上記のエイリアス OPTIMIZE TABLE tbl REWRITE DATA;
追記: コンパクションについては『Hive Iceberg Compaction: テーブル最適化の仕組みと実践 - おくみん公式ブログ』で詳しく説明しています。
不要なスナップショットの定期削除
Icebergが提供するブランチやタイムトラベル、ロールバックといった機能はデータエンジニアに新たな可能性を与えてくれます。何か不可解なことが起きたときに過去のデータに対してクエリしたり、最悪ある時点のデータに戻したりする仕組みは信頼性を高める上で非常に便利です。とはいえあらゆるデータ・メタデータを大量に保持し続けてまで10年前と全く同じ状態でクエリできるようにしたい、という方はそう多くないでしょう。何事にもROIというものがありますからね。
となるとApache Sparkなどを用いて一定期間を経過したスナップショットやそれにより参照されなくなるParquetファイルを適宜削除していく作業が必要になります。今は手動でなんとかなっている人もいるかもしれません。しかしテーブル数が増えるとその運用は困難を極めるでしょう。
先日GitHubを眺めていると、スナップショットを定期削除する機能がHiveに追加されようとしているのを見つけました。これはうまく育つと非常に便利だと思い、積極的にレビューすることにしています。Hiveは定期的にACIDテーブルのデータをコンパクションする機能も持っており、将来的にはIcebergテーブルを自動メンテナンスするための最も容易な手段の一つになるんじゃないかと思っています。
コンピュートエンジンとしてのHive
最後に説明するのは、クエリエンジンとしてのHiveとそのIceberg対応についてです。Icebergは比較的ベンダーニュートラルな立ち位置にいるため、用途に応じてクエリエンジンを使い分けるのが一般的だと思います。例えばETL処理はSparkで実行して、BIツールからの読み込みはTrinoで行うといった具合に。Hive自体もApache TezやLLAPによりかなり高性能になっており、Icebergとの連携は性能や使い勝手含め特に重点的に強化されています。
Iceberg REST Catalogサポート
クエリエンジンとしてのHiveはHive Metastoreと密結合しており、基本的にはHive Metastore以外のメタデータリポジトリを使用することができません*4。
ところが先程も申し上げた通り、今後は様々なベンダーがIceberg REST APIを提供し始めると思います。そこで、HMSをデプロイせずともそれらのカタログにHiveがダイレクトにアクセスできるよう、『[HIVE-28658] Iceberg REST Catalog client - ASF JIRA』が作成されました。前提となっている変更のレビューが大変ですが、各種ベンダーにとって非常に重要な変更なのでなんとかしてマージします。
まとめ
最近気になったIceberg系の面白プロジェクトを紹介しました。長くデータプラットフォームを支えてきただけあって、Hiveには新たなパラダイムに即座に応用できる基盤がいくつも備わっています。特にカタログとストレージエンジンの役割を両方こなせるオープンなプロダクトは限られているため、実はHiveはデータレイクハウス時代にこそ輝くのではないかと考えています。この思想は冒頭のMLでも共有した『Hive: Operating System for Data Lakehouse』というドキュメントにまとめてあるので、興味があればご参照ください。
とはいえコミュニティのリソースは限られているので、すべてがすんなり開発できるとは思えません。もし協力してくれる方がいれば、ぜひXやLinkedinまでご連絡ください!レビューやコミュニケーションの面で支援させていただきます。
宣伝
蛯原さんや佐野さんの尽力により、『Apache Iceberg: The Definitive Guide』の翻訳プロジェクトが発足し、私も微力ながらレビューをお手伝いしています。よい本になりそうなので、気が早いかもしれませんが宣伝させてください。
昨夜のApache Iceberg Japan Meetupで、運営の蛯原さんによる翻訳本の出版予定が発表されました🎉
— べりんぐ (@_Bassari) February 22, 2025
わたしもレビューに参加させていただきました。ぜひチェックを! #iceberg_jp pic.twitter.com/xudL31szh5
関連記事
*1:例: HIVE-28840, HIVE-28841
*2:SparkのStorage Partitioned JoinやHiveのPartition-Aware Optimizationはパーティション定義に応じて実行計画を変更する
*3:Icebergとは異なるアプローチでデータレイクに対してCRUDなどの操作を行えるようにする試み
*4:Amazon EMRのHiveはAWS Glue Data Catalogを使用できますが、あれは独自のパッチ(HIVE-12679)をあてることで実現しています