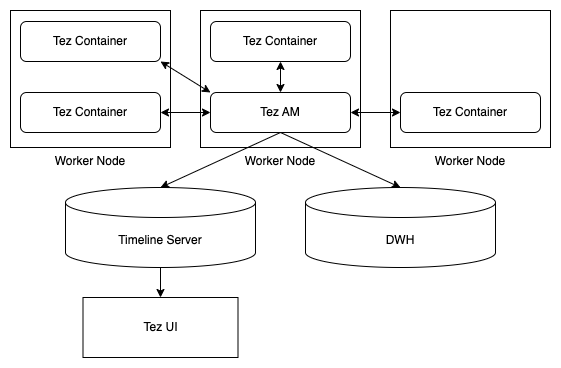
2023年に取り組んだ分散処理OSSに対する貢献のまとめです。今年はApache Hiveのコミュニティが活性化したのでHiveやTezに対する貢献が多めです。
この記事は『Distributed computing (Apache Spark, Hadoop, Kafka, ...)のカレンダー | Advent Calendar 2023 - Qiita』24日目として執筆しました。若干遅れて申し訳ございません。
続きを読む
2023年に取り組んだ分散処理OSSに対する貢献のまとめです。今年はApache Hiveのコミュニティが活性化したのでHiveやTezに対する貢献が多めです。
この記事は『Distributed computing (Apache Spark, Hadoop, Kafka, ...)のカレンダー | Advent Calendar 2023 - Qiita』24日目として執筆しました。若干遅れて申し訳ございません。
続きを読む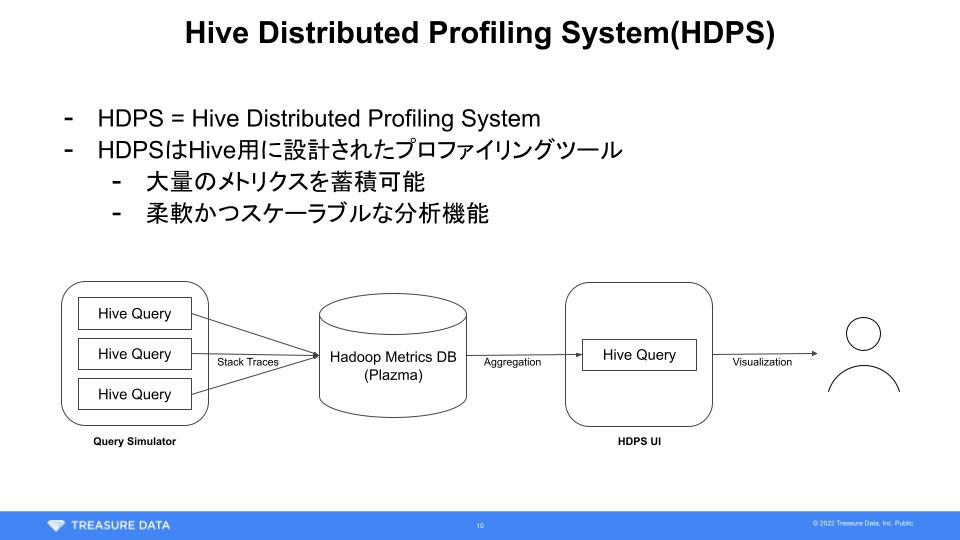
TreasureData Tech Talk 2022で発表した内容の補足です。Hive Distributed Profiling Systemの実装方法について、プレゼンテーション中に説明しきれなかった部分を解説します。なお本記事は「Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2022」19日目の記事として執筆しました。
続きを読む先日行われたTreasure Dataのイベントにて登壇させていただきました。タイトルは『Hive Distributed Profiling System in Treasure Data』。

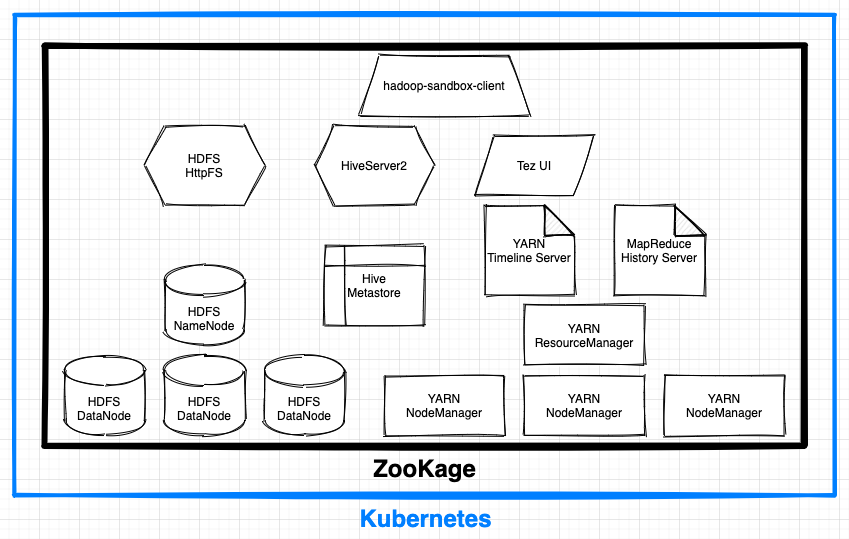
Kubernetes上にHadoopサンドボックス環境をコマンド一発で構築するツール、ZooKageをリリースしました。本記事では開発に至った経緯と基本的な使い方を紹介します。
「Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2020」にエントリーするつもりでいましたが、開発中に枠が埋まってしまったので過去の日付を埋める形で参加させていただきます。遅くなってすみません……
続きを読む
平成三十一年四月十四日をもって株式会社ドワンゴを退職しました。
そのご報告と、ほぼプログラミング経験のない自分をエンジニアとして採用し、様々な経験を積ませていただいたドワンゴの皆様へ感謝をお伝えしたいと思います。